

So most of the people who have been exposed to the Machine Learning and Data Science domain have come across Numpy either directly or indirectly.
You could be a newbie who just watched an “intro to ML” video or a Kaggle GrandMaster with 10 years of experience under his belt, but one thing that is common to both is Numpy. That’s how popular this library is. It is a fundamental building block for anybody interested in ML domain.
Even people who have done linear algebra in python have come across it one way or another. It’s the most popular scientific computing library, if you don’t know about it what are you even doing. DUH
So it’s no surprise that there is tons of good content available about it. But very few of them actually go into the the internals and theoretical part of it.
So here I am, with a piece that will blow your mind 🤯, and by the end of it, you will be able to understand how Numpy works and why so many libraries like Pandas, Scikit-Learn and TensorFlow prefer to use it.
This article is kind of long, so here is an index for you 😃.
Numpy, What is it ?
NumPy is the fundamental package for scientific computing in Python. Thats what the docs 📓 say, so is that all ?
❌❌❌ WRONG ❌❌❌
Numpy is not just that, it is much more. It is the Usain Bolt 🏃 of mathematical computation in python.
It is the package that converts your slow 🐢 python for loops into vectorized speed machines. It literally increases your computation speed by almost 100 times.
Don’t believe me, then believe the code 👇
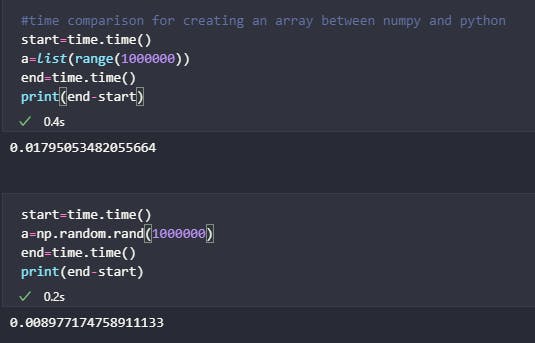
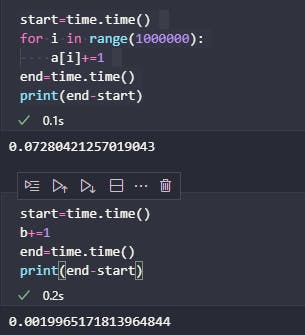 The code in the left image is almost 2x faster and in the right image is 36x faster 🤯
The code in the left image is almost 2x faster and in the right image is 36x faster 🤯
It is not just the bread 🍞 and butter 🧈 of your Machine Learning sandwich 🥪, it is the toaster, and a damn good one. And do you know what the differentiating factor between a good toaster and a bad toaster is ? The time it takes to make the toast crispy, and the taste of the finished toast.
Numpy is not much different, the time here refers to computational time and the taste is the syntax of your finished code.
So…
Why is it so fast ⚡ ?
There are quite a few reasons why Numpy is so much faster compared to traditional python code.
Language and Compiler.
Vectorization
Specially optimized code for different operations (arrays, linear algebra, etc.) .
1. Language and Compiler💬
So what do I mean when I say language. Is it the python syntax one uses when writing Numpy code? No. It is the language that Numpy itself is written in.
One of the main reasons why Numpy is so fast is that it is written in C and Fortran, yeah the one that came out in 1957. 💻
Now, python is a dynamic language, that is interpreted by the cpython interpreter, turned into bytecode and then executed. Now python is by no means slow, but you can’t compare it to compiled C code. 🐢 ≠ 🐇
Function calls and loops are almost 100–200 times faster in C, compared to Python. This gives Numpy a huge performance and speed boost.
To know why python is so slow check out this blog 👇
Why is Python so slow?
Python is booming in popularity. It is used in DevOps, Data Science, Web Development and Security.hackernoon.com
But how does one write a python package in another language and how does Numpy use them to speed things up?
So, generally speaking there are some libraries in python that will help you execute your C code in a python environment, significantly boosting your code performance.
For this you just write the desired function in C. Make sure to use pointers while working with arrays for maximum efficiency. Then compile it to create a .sofile that can be used in a python program.
To sum it up.
- Write a function in C.
- Compile it to get the
.sofile. 💻 - Use it in the python code. 🐍
To know more about this check out this amazing medium blog 👇
Calling C functions from Python
And how to interact with Numpy arrays in Cmedium.com
Another way you can speed up Numpy, is to use the Numba compiler. It is an open source **JIT** compiler that translates python code to optimized machine code at runtime using the LLVM compiler library.
You can find more about it over here 👇
Numba: A High Performance Python Compiler
@jit(nopython=True, parallel=True) def simulator(out): # iterate loop in parallel for i in prange(out.shape[0]): out[i]…numba.pydata.org
As to what compiler Numpy is compiled on, it is GNU, MSVC and Clang.
Now you know that by using C and Fortran Numpy can do calculations at a faster speed than normal python. 🐢 -> 🐇
2. Vectorization
The above section made it clear how Numpy makes python fast. But how to make it blazingly fast ? 🐇 -> 🚀
The answer. Vectoriztion.
](https://cdn-images-1.medium.com/max/2000/0*ovabJqb3xO540OPV.jpg) https://www.quantifisolutions.com/Data/Sites/1/media/blog-images/vectorization/3.jpg
https://www.quantifisolutions.com/Data/Sites/1/media/blog-images/vectorization/3.jpg
Now, you might have heard about vectorization, a lot of people use that term without fully understanding what that means. But what does it actually stand for?
Vectorization is the process of carrying out multiple operations at once to increase the computational speed.
Do not confuse it with the concept of concurrency), vectorization is related to data parallelism. They may sound similar but actually are quite a bit different.
Lets say there are 4 processes that take 10 seconds each. Now if we run them in a sequential manner process 1 will be executed first, then after 10 seconds process 2 will be executed and so on. The total run time will be 40 seconds, and the processes will be completed one after another.
Concurrency basically means that you deal with all the processes at once. Now, hold on. It doesn’t mean that all the processes run at the same time and get completed in 10 seconds. That’s parallelism. In concurrent computing you use a single core, and use concepts like First Come First Serve (FCFS), Round Robin (RR) and others to simultaneously execute the process. The total tine will still be 40 seconds but the processes will be completed at once or without much difference in their finish time. This is mainly used in web servers and cloud ☁️ computing when a lot of queries need to be solved simultaneously.
Parallelism basically means that you split the processes across multiple cores. So instead of taking 40 seconds to complete the entire task. It takes only 10 seconds 🤯 , assuming you have 4 cores and all the processes run on an independent core or processor. The individual execution time will still be 10 seconds per process. It’s just that the processes run parallelly. One thing that you need to keep in mind is that the Locality of Reference plays an integral part in the performance of the parallel task.
So, now that you know how parallelism reduces the computation time. Lets see how this affects vectorization.
Now vectorization uses SIMD (Single Instruction Multiple Data) instructions in the processor to make the code faster. So it basically executes the same instruction over all the different data points at once.
So, lets say you have an array with 10 elements and you want to add 1 to all of it. Using vectorization you can do this in just one step, instead of 10. So the code is now 10 times faster, almost. You do need to take in account the time it would take to merge the results, and the extra time due to the overhead. But that is negligible compared to how much time you are actually saving.
Lets look at an example 👇
Suppose your computer has an AVX512 instruction set, that means you can work on 16 integers at the same time. So if you have a vector of 16 integers, you can either load them into the general register one by one and execute the instruction.
Or…
You could load all 16 values on the SIMD register at the same time and execute the instruction only once. This will decrease the computation time from “N” to “N/16”. 🤯
If your register can hold more values, it will be even faster. 🚀
Thus, Vectorization combined with the Language can make your python code blazingly fast. 🐇 -> 🚀
3. Individual Optimizations
The code is already blazingly fast, but it can become even faster if we individually optimize the code on the basis of the operation. Now if I went over all the optimizations I would be an old man 👴 by the time this blog ended. So I will only cover certain array optimizations, and how Numpy speeds up array operations, since they are an intrinsic part of the Numpy ecosystem.
But to understand what makes these arrays so fast, first we need to look at what makes it different from a standard python list.
So a standard python list object is mutable and can contain different types of elements (integers, strings, etc.). This results in a lot of overhead which stores the metadata of the list and its elements.
Lets look at an example 👇
Lets assume a list of “n” elements, for the sake of simplicity lets assume that they are all integers. Now integers in python list are generally 32 bit .i.e. they require 4 bytes of space. Now the additional overhead that this list’s elements have can be summed up as 4 things.
Size: The size of the object. (In this case 4 bytes)
Object Value: The bits of the object.
Object Type: The type of the object.
Reference Count: The amount of time this object has been called. Used for garbage collection and memory management.
Now all these are roughly 4 bytes each, so 4*4 that’s 16 bytes of memory. They can also be 8 bytes, so it can even go up to 32 bytes.
That’s a lot of memory compared to a Numpy array element which is only 4 bytes in size assuming its an int32 object.
This memory difference helps in reducing computation time.
Another reason why Numpy arrays are faster is that they utilize contiguous memory, unlike python lists where elements can be scattered around. And since the data instances are in the same set of memory locations, it is possible to apply data parallelism concepts .i.e. vectorization due to the principle of locality of reference.
So coming to a conclusion we can say that by utilizing the power of vectorization and individual optimizations also coupled with the fact that the operations are written in C, Numpy code is often times faster than even C++ code 🤯. Which is way faster than normal python code.
If you want to know more about such individual optimizations, take a look at the Numpy docs 👇
NumPy Documentation
Edit descriptionnumpy.org
Also take a look at this awesome video by FreeCodeCamp, if you want to learn some basic Numpy 👇
That’s it. I hope you enjoyed the read ❤️.
Burhanuddin Rangwala the author of this blog is an aspiring Data Scientist and Machine Learning Engineer who also works as a freelance Web Developer and Writer. Hit him up at LinkedIn or Twitter for any work or freelance related opportunities. Or just drop a 👋
JavaScript is not available. Edit descriptiontwitter.com
Burhanuddin Rangwala - Community Mentor - Somaiya Machine Learning Research Association (SMLRA) |… View Burhanuddin Rangwala's profile on LinkedIn, the world's largest professional community. Burhanuddin has 7 jobs…linkedin.com