

Anybody who has dabbled in data science knows how important it is to select the correct features and model parameters for generating a good model, especially in tasks that involve tabular data. Feature selection is the crux of any data modelling pipeline and it is different from use-case to use-case.
Here is where autoML comes in, it basically automates the process of feature and model selection. There are a bunch of autoML libraries out there like TPOT, MLJar, auto-sklearn but today I am going to show you how to use LightAutoML. Compared to TPOT LightAutoML is very lightweight and runs model selection on the basis of time instead of generations and populations, so there is no situation that the computation took longer than expected.
Code
For this example I am just going to use random tabular data from kaggle. LightAutoML can run on your local machine but I recommend using Google Colab or Kaggle Notebooks for the GPU.
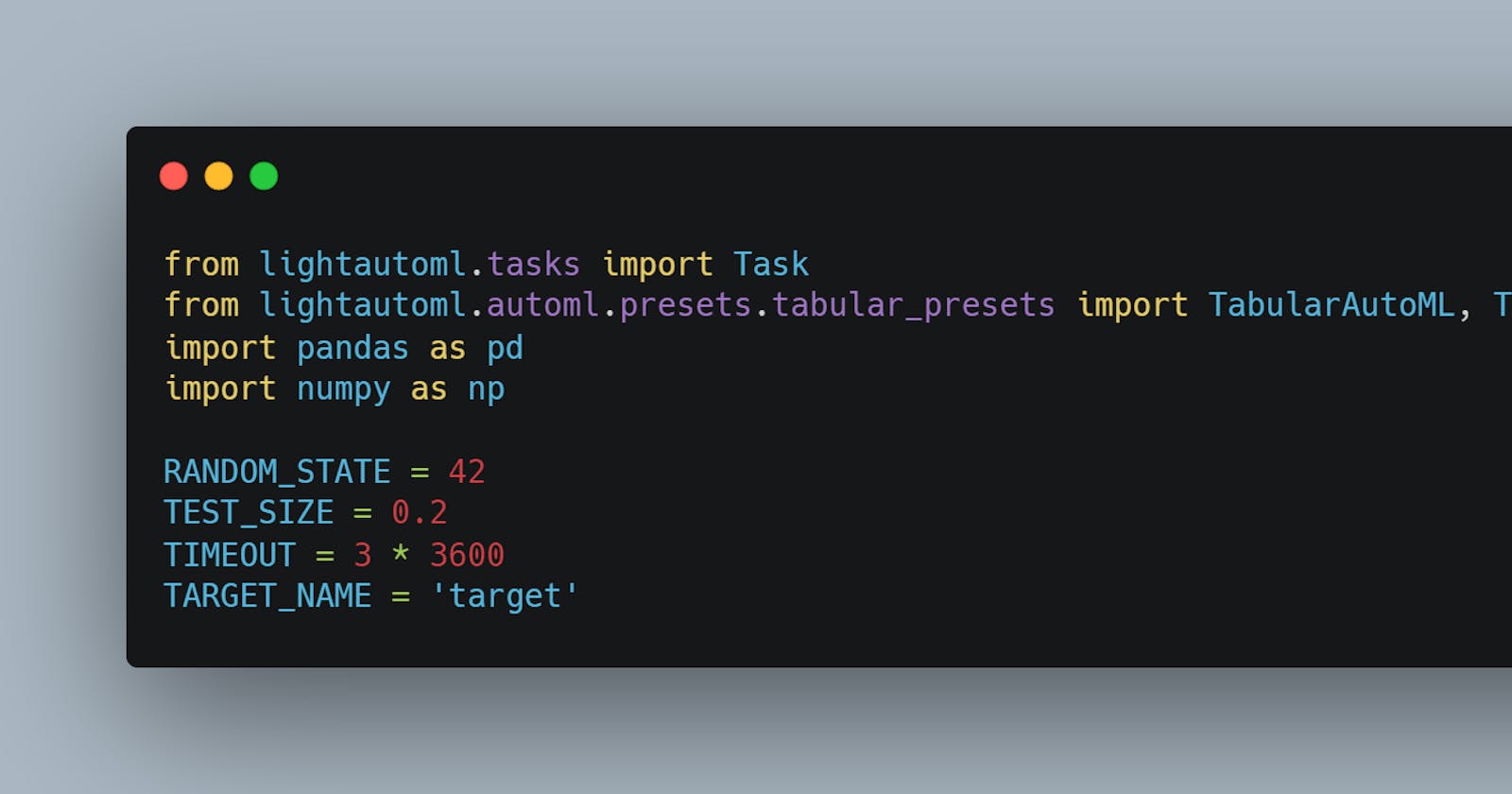
1. Install and setup the required libraries.
You can just install the libraries using pip.
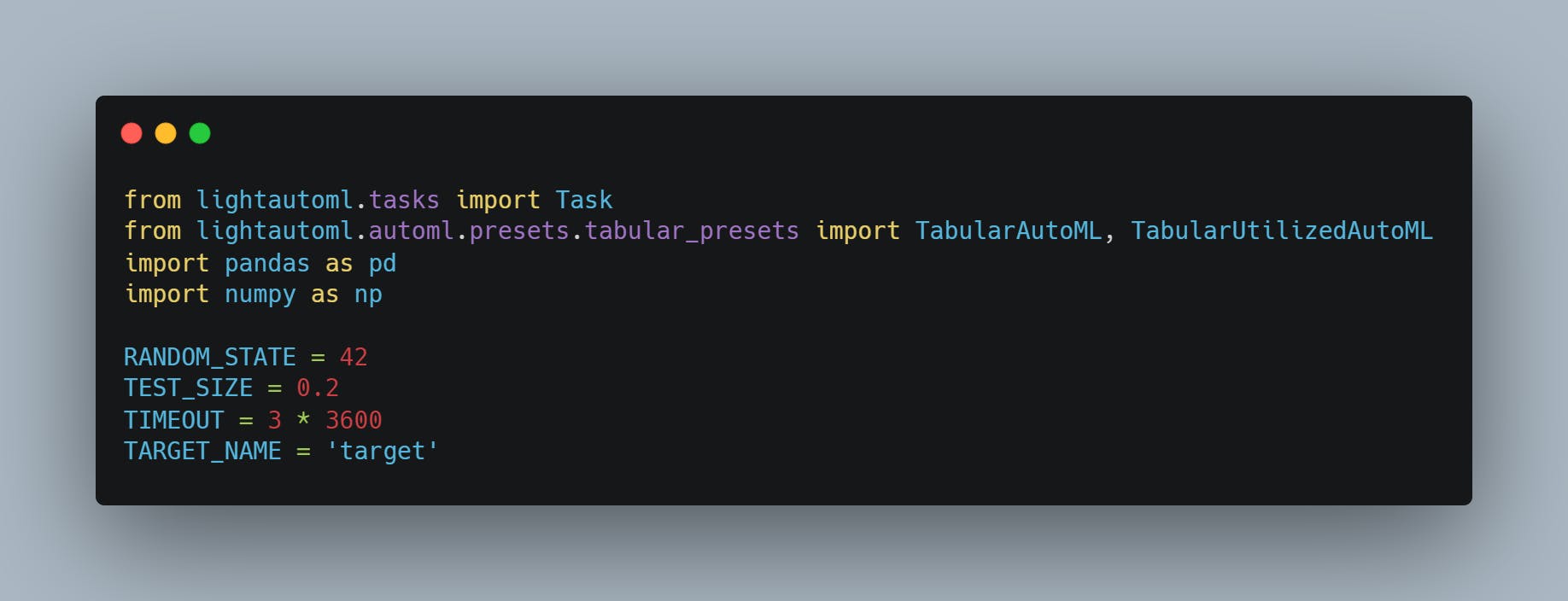
Here the target name refers to the column that needs to predicted, test size to the amount of data you want to use as test and timeout is the amount of time the instance will run.
2. Load in the data
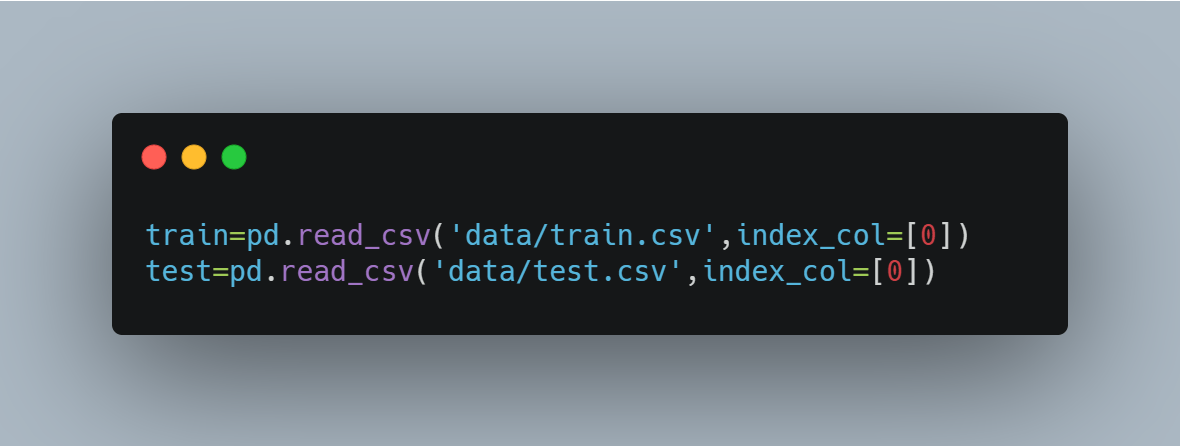
Create the train and test sets and make sure the target column is in a label encoded format. You can use the LabelEncoder from sklearn to do this easily.
3. Create the task and autoML instance
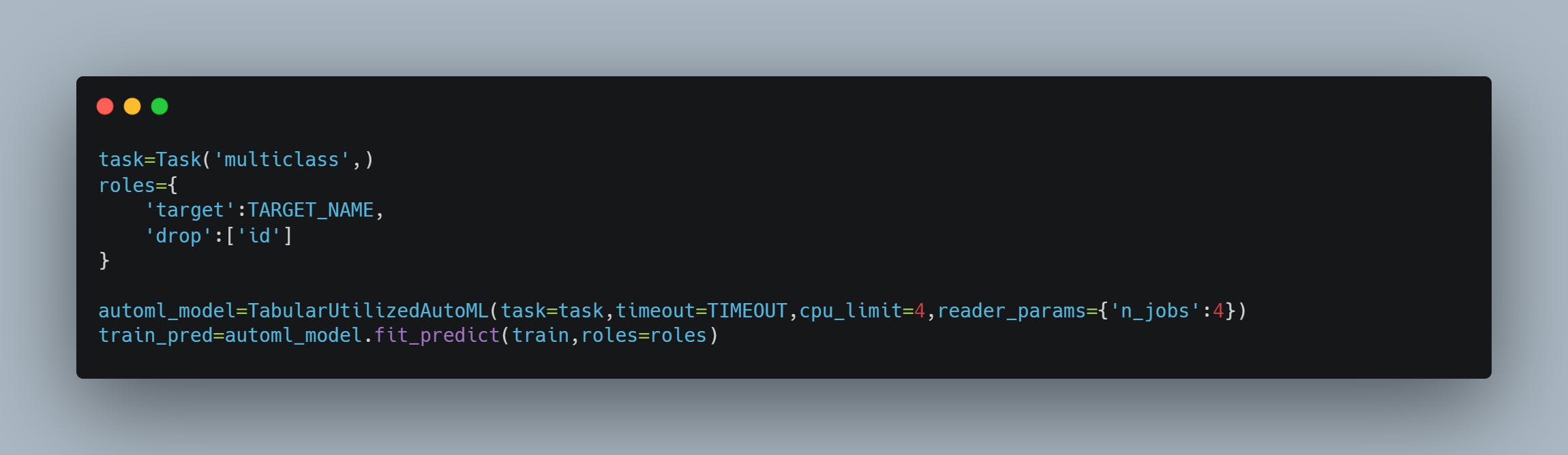
The above code will run for the duration of your timeout parameter. The greater the time the higher the chance of getting a better model. Though if the score doesn’t improve for a certain number of iterations it stops automatically.
Here the task is used to create a specific task in this case multiclass classification. The roles dictionary provides the model with necessary information like the name of the target column and the columns that need to be dropped. There are more hyperparameters to tweak so give the docs a go.
4. Inference and Plotting
The best fitted model is stored in the automl_model variable you can use this for predictions and getting feature scores.
First I will show you how to get the feature scores and even plot them.
The above code will plot the following graph.
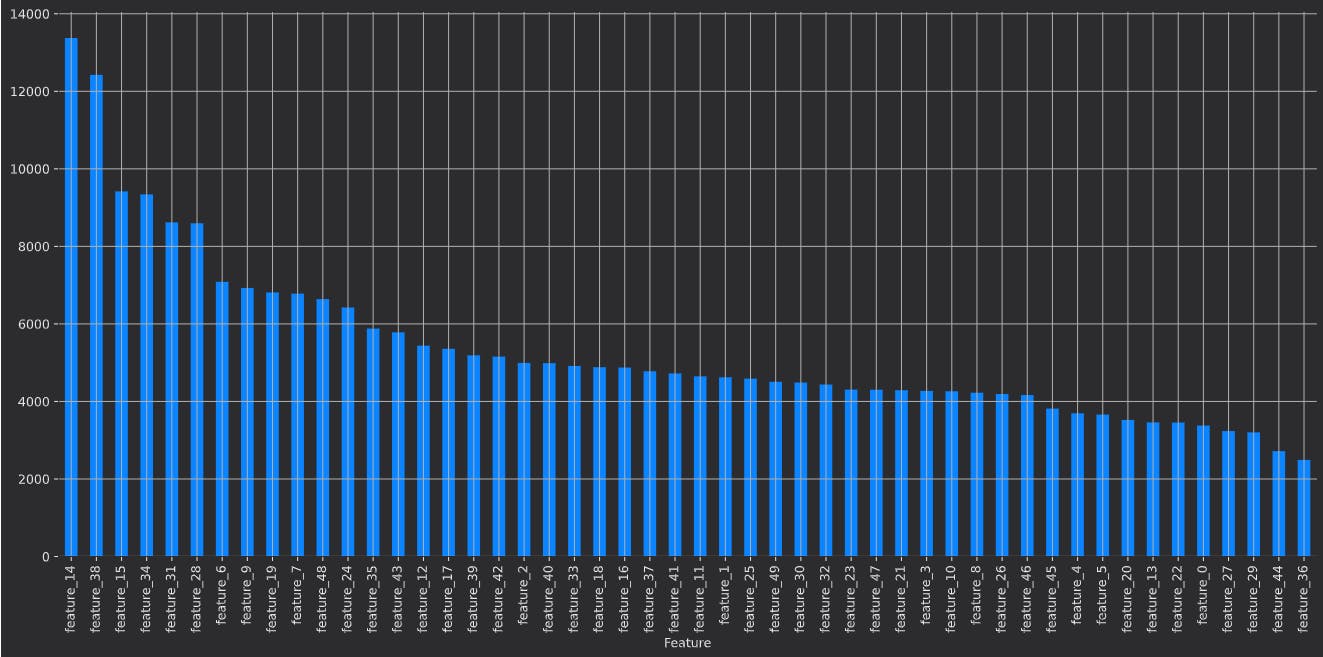
Here you can see that the get_feature_scores method returns an array of feature scores which we can plot for better explainability.
For inference

The predict method returns an 2-d array (number of instances x number of target classes) which contains the probabilities of an instance being a specific class on which we apply the argmax function to get the class to which the instance belongs to.
To save the model you can just use joblib or pickle. Though I recommend using joblib since the model files can get quite large.
And that’s it in less than 10 minutes you have written all the code required to train a model. With enough training time LightAutoML models can easily give a better score than your generic out of the mill sklearn models without any of the feature and model selection hassle. That’s how easy it is.
If you are interested in this domain also checkout the other autoML libraries like TPOT and auto-sklearn.