


In recent times the deep learning bandwagon is moving pretty fast. With all the different things you can do with it, its no surprise; images, tabular-data and all sorts of different media classification and generation algorithms have gotten quiet a boost. But one form of media that doesn’t get much love is audio. Being a huge music fan myself that’s bit of a bummer.
Recently while looking for some resources to build an audio regressor I realized that the amount of quality content for audio based ML is negligible as compared to that of other media formats. So I decided to write a little tutorial about it myself, something a bit different from the hackneyed Resnet-50 classification videos. 😏
Since covid-19 is the current hot topic right now I decided to build a audio regressor that can predict the amount of cough a person has. This is a regression model but if you want to learn to build a classification model I will cover that at the end. This blog is for both newbies as well as experienced people and will cover everything from the data preprocessing to the model creation. So lets get started.
1. Initialization
In this part I will just go over the libraries we need to import as well as how to acquire the data. if you already have some other data that you want to use feel free to skip this section.
import torch as pt
from torch import nn
import torchaudio as ta
from torchsummary import summary
from torch.utils.data import Dataset,DataLoader
import numpy as numpy
import os
import subprocess
import tqdm as tqdm
import json
if pt.cuda.is_available():
device='cuda'
else:
device='cpu'
class CoughVidDataset(Dataset):
def __init__(self,audio_path,label_path,transformation,target_sample_rate,num_samples,device):
name_set=set()
for file in os.listdir(audio_path):
if file.endswith('wav'):
name_set.add(file)
name_set=list(name_set)
self.datalist=name_set
self.audio_path=audio_path
self.label_path=label_path
self.device=device
self.transformation=transformation.to(device)
self.target_sample_rate=target_sample_rate
self.num_samples=num_samples
def __len__(self):
return len(self.datalist)
def __getitem__(self,idx):
audio_file_path=os.path.join(self.audio_path,self.datalist[idx])
label_file_path=os.path.join(self.label_path,self.datalist[idx][:-4]+'.json')
with open(label_file_path,'r') as f:
content=json.loads(f.read())
f.close()
label=content['cough_detected']
waveform,sample_rate=ta.load(audio_file_path) #(num_channels,samples) -> (1,samples) makes the waveform mono
waveform=waveform.to(self.device)
waveform=self._resample(waveform,sample_rate)
waveform=self._mix_down(waveform)
waveform=self._cut(waveform)
waveform=self._right_pad(waveform)
waveform=self.transformation(waveform)
return waveform,float(label)
def _resample(self,waveform,sample_rate):
# used to handle sample rate
resampler=ta.transforms.Resample(sample_rate,self.target_sample_rate)
return resampler(waveform)
def _mix_down(self,waveform):
# used to handle channels
waveform=pt.mean(waveform,dim=0,keepdim=True)
return waveform
def _cut(self,waveform):
# cuts the waveform if it has more than certain samples
if waveform.shape[1]>self.num_samples:
waveform=waveform[:,:self.num_samples]
return waveform
def _right_pad(self,waveform):
# pads the waveform if it has less than certain samples
signal_length=waveform.shape[1]
if signal_length<self.num_samples:
num_padding=self.num_samples-signal_length
last_dim_padding=(0,num_padding) # first arg for left second for right padding. Make a list of tuples for multi dim
waveform=pt.nn.functional.pad(waveform,last_dim_padding)
return waveform
melspectogram=ta.transforms.MelSpectrogram(sample_rate=SAMPLE_RATE,n_fft=1024,hop_length=512,n_mels=64)
class CNNNetwork(nn.Module):
def __init__(self):
super().__init__()
self.conv1=nn.Sequential(
nn.Conv2d(in_channels=1,out_channels=16,kernel_size=3,stride=1,padding=2),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2)
)
self.conv2=nn.Sequential(
nn.Conv2d(in_channels=16,out_channels=32,kernel_size=3,stride=1,padding=2),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2)
)
self.conv3=nn.Sequential(
nn.Conv2d(in_channels=32,out_channels=64,kernel_size=3,stride=1,padding=2),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2)
)
self.conv4=nn.Sequential(
nn.Conv2d(in_channels=64,out_channels=128,kernel_size=3,stride=1,padding=2),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2)
)
self.flatten=nn.Flatten()
self.linear1=nn.Linear(in_features=128*5*4,out_features=128)
self.linear2=nn.Linear(in_features=128,out_features=1)
self.output=nn.Sigmoid()
def forward(self,input_data):
x=self.conv1(input_data)
x=self.conv2(x)
x=self.conv3(x)
x=self.conv4(x)
x=self.flatten(x)
x=self.linear1(x)
logits=self.linear2(x)
output=self.output(logits)
return output
model=CNNNetwork().cuda()
summary(model,(1,64,44))
waveform,label=coughvid_dataset[0]
def predict(model,inputs,labels):
model.eval()
inputs=pt.unsqueeze(inputs,0)
with pt.no_grad():
predictions=model(inputs)
return predictions,labels
prediction,label=predict(model,waveform,label)
print(prediction,label)
audio_path='Path Where .wav files are stored'
label_path='Path Where json files are stored'
SAMPLE_RATE=22050
NUM_SAMPLES=22050
BATCH_SIZE=128
EPOCHS=1
melspectogram=ta.transforms.MelSpectrogram(sample_rate=SAMPLE_RATE,n_fft=1024,hop_length=512,n_mels=64)
coughvid_dataset=CoughVidDataset(audio_path,label_path,melspectogram,SAMPLE_RATE,NUM_SAMPLES,device)
train_dataloader=DataLoader(coughvid_dataset,batch_size=BATCH_SIZE,shuffle=True)
loss_fn=pt.nn.MSELoss()
optimizer=pt.optim.SGD(model.parameters(),lr=0.1,momentum=0.9)
train(model,train_dataloader,loss_fn,optimizer,device,EPOCHS)
def train_single_epoch(model,dataloader,loss_fn,optimizer,device):
for waveform,label in tqdm.tqdm(dataloader):
waveform=waveform.to(device)
# label=pt.from_numpy(numpy.array(label))
label=label.to(device)
# calculate loss and preds
logits=model(waveform)
loss=loss_fn(logits.float(),label.float().view(-1,1))
# backpropogate the loss and update the gradients
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f"loss:{loss.item()}")
def train(model,dataloader,loss_fn,optimizer,device,epochs):
for i in tqdm.tqdm(range(epochs)):
print(f"epoch:{i+1}")
train_single_epoch(model,dataloader,loss_fn,optimizer,device)
print('-------------------------------------------')
print('Finished Training')
path='Path Where .wav files are stored'
name_set=set()
for file in os.listdir(path):
if file.endswith('wav'):
name_set.add(file)
print(len(name_set))
t=os.path.join(path,list(name_set)[0])
label_path='Path where the json files are'
fname=t[8:-4]
l=os.path.join(label_path,fname+'.json')
print(fname)
with open(l,'r') as f:
content=json.loads(f.read())
print(content)
signal,sr=ta.load(t)
path='PathToFile'
for file in os.listdir(path):
if file.endswith('webm'):
subprocess.run(['ffmpeg','-i',os.path.join(path,file),'test_df/'+file[:-5]+'.wav'])
The above code will import all the necessary libraries and initialize your device to either CPU or GPU. Since the model won’t be that resource intensive a GPU isn’t necessary but it will be better if you have one. If you don’t have one just use google colab.
As for the data lets use the coughvid dataset. You can download it from over here https://zenodo.org/record/4498364.
The public version of the dataset contains around 2000 audio files that contain audio samples from subjects representing a wide range of gender, age, geographic location, and covid-19 statuses that have been labeled by experienced pulmonologists.
2. Data Preprocessing
In this step I will go over the entire data preprocessing and pytorch dataset creation pipeline. But first of all lets take a look at the data.
The audio files are in the .webm format and the config data is in the JSON format. One big problem here is that if the audio data is not in the .wav format pytorch gets really fussy about it. And believe me converting the file formats without corrupting them is a nightmare if it is your first time doing this. But don’t worry I have a script that does the job for you.
import torch as pt
from torch import nn
import torchaudio as ta
from torchsummary import summary
from torch.utils.data import Dataset,DataLoader
import numpy as numpy
import os
import subprocess
import tqdm as tqdm
import json
if pt.cuda.is_available():
device='cuda'
else:
device='cpu'
class CoughVidDataset(Dataset):
def __init__(self,audio_path,label_path,transformation,target_sample_rate,num_samples,device):
name_set=set()
for file in os.listdir(audio_path):
if file.endswith('wav'):
name_set.add(file)
name_set=list(name_set)
self.datalist=name_set
self.audio_path=audio_path
self.label_path=label_path
self.device=device
self.transformation=transformation.to(device)
self.target_sample_rate=target_sample_rate
self.num_samples=num_samples
def __len__(self):
return len(self.datalist)
def __getitem__(self,idx):
audio_file_path=os.path.join(self.audio_path,self.datalist[idx])
label_file_path=os.path.join(self.label_path,self.datalist[idx][:-4]+'.json')
with open(label_file_path,'r') as f:
content=json.loads(f.read())
f.close()
label=content['cough_detected']
waveform,sample_rate=ta.load(audio_file_path) #(num_channels,samples) -> (1,samples) makes the waveform mono
waveform=waveform.to(self.device)
waveform=self._resample(waveform,sample_rate)
waveform=self._mix_down(waveform)
waveform=self._cut(waveform)
waveform=self._right_pad(waveform)
waveform=self.transformation(waveform)
return waveform,float(label)
def _resample(self,waveform,sample_rate):
# used to handle sample rate
resampler=ta.transforms.Resample(sample_rate,self.target_sample_rate)
return resampler(waveform)
def _mix_down(self,waveform):
# used to handle channels
waveform=pt.mean(waveform,dim=0,keepdim=True)
return waveform
def _cut(self,waveform):
# cuts the waveform if it has more than certain samples
if waveform.shape[1]>self.num_samples:
waveform=waveform[:,:self.num_samples]
return waveform
def _right_pad(self,waveform):
# pads the waveform if it has less than certain samples
signal_length=waveform.shape[1]
if signal_length<self.num_samples:
num_padding=self.num_samples-signal_length
last_dim_padding=(0,num_padding) # first arg for left second for right padding. Make a list of tuples for multi dim
waveform=pt.nn.functional.pad(waveform,last_dim_padding)
return waveform
melspectogram=ta.transforms.MelSpectrogram(sample_rate=SAMPLE_RATE,n_fft=1024,hop_length=512,n_mels=64)
class CNNNetwork(nn.Module):
def __init__(self):
super().__init__()
self.conv1=nn.Sequential(
nn.Conv2d(in_channels=1,out_channels=16,kernel_size=3,stride=1,padding=2),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2)
)
self.conv2=nn.Sequential(
nn.Conv2d(in_channels=16,out_channels=32,kernel_size=3,stride=1,padding=2),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2)
)
self.conv3=nn.Sequential(
nn.Conv2d(in_channels=32,out_channels=64,kernel_size=3,stride=1,padding=2),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2)
)
self.conv4=nn.Sequential(
nn.Conv2d(in_channels=64,out_channels=128,kernel_size=3,stride=1,padding=2),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2)
)
self.flatten=nn.Flatten()
self.linear1=nn.Linear(in_features=128*5*4,out_features=128)
self.linear2=nn.Linear(in_features=128,out_features=1)
self.output=nn.Sigmoid()
def forward(self,input_data):
x=self.conv1(input_data)
x=self.conv2(x)
x=self.conv3(x)
x=self.conv4(x)
x=self.flatten(x)
x=self.linear1(x)
logits=self.linear2(x)
output=self.output(logits)
return output
model=CNNNetwork().cuda()
summary(model,(1,64,44))
waveform,label=coughvid_dataset[0]
def predict(model,inputs,labels):
model.eval()
inputs=pt.unsqueeze(inputs,0)
with pt.no_grad():
predictions=model(inputs)
return predictions,labels
prediction,label=predict(model,waveform,label)
print(prediction,label)
audio_path='Path Where .wav files are stored'
label_path='Path Where json files are stored'
SAMPLE_RATE=22050
NUM_SAMPLES=22050
BATCH_SIZE=128
EPOCHS=1
melspectogram=ta.transforms.MelSpectrogram(sample_rate=SAMPLE_RATE,n_fft=1024,hop_length=512,n_mels=64)
coughvid_dataset=CoughVidDataset(audio_path,label_path,melspectogram,SAMPLE_RATE,NUM_SAMPLES,device)
train_dataloader=DataLoader(coughvid_dataset,batch_size=BATCH_SIZE,shuffle=True)
loss_fn=pt.nn.MSELoss()
optimizer=pt.optim.SGD(model.parameters(),lr=0.1,momentum=0.9)
train(model,train_dataloader,loss_fn,optimizer,device,EPOCHS)
def train_single_epoch(model,dataloader,loss_fn,optimizer,device):
for waveform,label in tqdm.tqdm(dataloader):
waveform=waveform.to(device)
# label=pt.from_numpy(numpy.array(label))
label=label.to(device)
# calculate loss and preds
logits=model(waveform)
loss=loss_fn(logits.float(),label.float().view(-1,1))
# backpropogate the loss and update the gradients
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f"loss:{loss.item()}")
def train(model,dataloader,loss_fn,optimizer,device,epochs):
for i in tqdm.tqdm(range(epochs)):
print(f"epoch:{i+1}")
train_single_epoch(model,dataloader,loss_fn,optimizer,device)
print('-------------------------------------------')
print('Finished Training')
path='Path Where .wav files are stored'
name_set=set()
for file in os.listdir(path):
if file.endswith('wav'):
name_set.add(file)
print(len(name_set))
t=os.path.join(path,list(name_set)[0])
label_path='Path where the json files are'
fname=t[8:-4]
l=os.path.join(label_path,fname+'.json')
print(fname)
with open(l,'r') as f:
content=json.loads(f.read())
print(content)
signal,sr=ta.load(t)
path='PathToFile'
for file in os.listdir(path):
if file.endswith('webm'):
subprocess.run(['ffmpeg','-i',os.path.join(path,file),'test_df/'+file[:-5]+'.wav'])
This script uses ffmpeg which is a command line tool used to convert audio and video formats (seriously this is very useful for modifying datasets) to convert all the .webm files to .wav files. Note that this will take quiet some time depending on your hardware and also that the size of .wav files is 8–10 times that of .webm files so make sure you have the storage space for that. You can delete the .webm files after this though make sure not to modify the JSON files.
Now lets actually come to the viewing the data part (I know we have taken a long detour 😅).
import torch as pt
from torch import nn
import torchaudio as ta
from torchsummary import summary
from torch.utils.data import Dataset,DataLoader
import numpy as numpy
import os
import subprocess
import tqdm as tqdm
import json
if pt.cuda.is_available():
device='cuda'
else:
device='cpu'
class CoughVidDataset(Dataset):
def __init__(self,audio_path,label_path,transformation,target_sample_rate,num_samples,device):
name_set=set()
for file in os.listdir(audio_path):
if file.endswith('wav'):
name_set.add(file)
name_set=list(name_set)
self.datalist=name_set
self.audio_path=audio_path
self.label_path=label_path
self.device=device
self.transformation=transformation.to(device)
self.target_sample_rate=target_sample_rate
self.num_samples=num_samples
def __len__(self):
return len(self.datalist)
def __getitem__(self,idx):
audio_file_path=os.path.join(self.audio_path,self.datalist[idx])
label_file_path=os.path.join(self.label_path,self.datalist[idx][:-4]+'.json')
with open(label_file_path,'r') as f:
content=json.loads(f.read())
f.close()
label=content['cough_detected']
waveform,sample_rate=ta.load(audio_file_path) #(num_channels,samples) -> (1,samples) makes the waveform mono
waveform=waveform.to(self.device)
waveform=self._resample(waveform,sample_rate)
waveform=self._mix_down(waveform)
waveform=self._cut(waveform)
waveform=self._right_pad(waveform)
waveform=self.transformation(waveform)
return waveform,float(label)
def _resample(self,waveform,sample_rate):
# used to handle sample rate
resampler=ta.transforms.Resample(sample_rate,self.target_sample_rate)
return resampler(waveform)
def _mix_down(self,waveform):
# used to handle channels
waveform=pt.mean(waveform,dim=0,keepdim=True)
return waveform
def _cut(self,waveform):
# cuts the waveform if it has more than certain samples
if waveform.shape[1]>self.num_samples:
waveform=waveform[:,:self.num_samples]
return waveform
def _right_pad(self,waveform):
# pads the waveform if it has less than certain samples
signal_length=waveform.shape[1]
if signal_length<self.num_samples:
num_padding=self.num_samples-signal_length
last_dim_padding=(0,num_padding) # first arg for left second for right padding. Make a list of tuples for multi dim
waveform=pt.nn.functional.pad(waveform,last_dim_padding)
return waveform
melspectogram=ta.transforms.MelSpectrogram(sample_rate=SAMPLE_RATE,n_fft=1024,hop_length=512,n_mels=64)
class CNNNetwork(nn.Module):
def __init__(self):
super().__init__()
self.conv1=nn.Sequential(
nn.Conv2d(in_channels=1,out_channels=16,kernel_size=3,stride=1,padding=2),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2)
)
self.conv2=nn.Sequential(
nn.Conv2d(in_channels=16,out_channels=32,kernel_size=3,stride=1,padding=2),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2)
)
self.conv3=nn.Sequential(
nn.Conv2d(in_channels=32,out_channels=64,kernel_size=3,stride=1,padding=2),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2)
)
self.conv4=nn.Sequential(
nn.Conv2d(in_channels=64,out_channels=128,kernel_size=3,stride=1,padding=2),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2)
)
self.flatten=nn.Flatten()
self.linear1=nn.Linear(in_features=128*5*4,out_features=128)
self.linear2=nn.Linear(in_features=128,out_features=1)
self.output=nn.Sigmoid()
def forward(self,input_data):
x=self.conv1(input_data)
x=self.conv2(x)
x=self.conv3(x)
x=self.conv4(x)
x=self.flatten(x)
x=self.linear1(x)
logits=self.linear2(x)
output=self.output(logits)
return output
model=CNNNetwork().cuda()
summary(model,(1,64,44))
waveform,label=coughvid_dataset[0]
def predict(model,inputs,labels):
model.eval()
inputs=pt.unsqueeze(inputs,0)
with pt.no_grad():
predictions=model(inputs)
return predictions,labels
prediction,label=predict(model,waveform,label)
print(prediction,label)
audio_path='Path Where .wav files are stored'
label_path='Path Where json files are stored'
SAMPLE_RATE=22050
NUM_SAMPLES=22050
BATCH_SIZE=128
EPOCHS=1
melspectogram=ta.transforms.MelSpectrogram(sample_rate=SAMPLE_RATE,n_fft=1024,hop_length=512,n_mels=64)
coughvid_dataset=CoughVidDataset(audio_path,label_path,melspectogram,SAMPLE_RATE,NUM_SAMPLES,device)
train_dataloader=DataLoader(coughvid_dataset,batch_size=BATCH_SIZE,shuffle=True)
loss_fn=pt.nn.MSELoss()
optimizer=pt.optim.SGD(model.parameters(),lr=0.1,momentum=0.9)
train(model,train_dataloader,loss_fn,optimizer,device,EPOCHS)
def train_single_epoch(model,dataloader,loss_fn,optimizer,device):
for waveform,label in tqdm.tqdm(dataloader):
waveform=waveform.to(device)
# label=pt.from_numpy(numpy.array(label))
label=label.to(device)
# calculate loss and preds
logits=model(waveform)
loss=loss_fn(logits.float(),label.float().view(-1,1))
# backpropogate the loss and update the gradients
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f"loss:{loss.item()}")
def train(model,dataloader,loss_fn,optimizer,device,epochs):
for i in tqdm.tqdm(range(epochs)):
print(f"epoch:{i+1}")
train_single_epoch(model,dataloader,loss_fn,optimizer,device)
print('-------------------------------------------')
print('Finished Training')
path='Path Where .wav files are stored'
name_set=set()
for file in os.listdir(path):
if file.endswith('wav'):
name_set.add(file)
print(len(name_set))
t=os.path.join(path,list(name_set)[0])
label_path='Path where the json files are'
fname=t[8:-4]
l=os.path.join(label_path,fname+'.json')
print(fname)
with open(l,'r') as f:
content=json.loads(f.read())
print(content)
signal,sr=ta.load(t)
path='PathToFile'
for file in os.listdir(path):
if file.endswith('webm'):
subprocess.run(['ffmpeg','-i',os.path.join(path,file),'test_df/'+file[:-5]+'.wav'])
The name_set just stores the names of all the files so that we can easily refer to them via index in the pytorch dataset. I will cover this later. So now lets view the content which contains data about our subject.
 Subject Content
Subject Content
As you can see above we have lot of different information about the subject like his age, geographical location and the amount of cough he has. The ‘cough_detected’ parameter here is our label. This is what we want our ML model to predict.
Now lets look at the last line of the code block. Here we are using the load method which returns to us the waveform which is a tensor of the shape [channels, time] and the sample rate. The waveform basically is a 2d array of frequencies over time with ‘sample rate’ intervals per second that we feed to our ML model.
If all these terms seem abstruse to you try reading this blog that gives you some some insight about sample rate, bit rate, etc. https://www.vocitec.com/docs-tools/blog/sampling-rates-sample-depths-and-bit-rates-basic-audio-concepts
Now lets build the pytorch dataset. This can be a little overwhelming if it is your first time working with audio so just refer to the torch audio documentation if you don’t understand something. torchaudio - Torchaudio 0.9.0 documentation This library is part of the PyTorch project. PyTorch is an open source machine learning framework. Features described…pytorch.org
import torch as pt
from torch import nn
import torchaudio as ta
from torchsummary import summary
from torch.utils.data import Dataset,DataLoader
import numpy as numpy
import os
import subprocess
import tqdm as tqdm
import json
if pt.cuda.is_available():
device='cuda'
else:
device='cpu'
class CoughVidDataset(Dataset):
def __init__(self,audio_path,label_path,transformation,target_sample_rate,num_samples,device):
name_set=set()
for file in os.listdir(audio_path):
if file.endswith('wav'):
name_set.add(file)
name_set=list(name_set)
self.datalist=name_set
self.audio_path=audio_path
self.label_path=label_path
self.device=device
self.transformation=transformation.to(device)
self.target_sample_rate=target_sample_rate
self.num_samples=num_samples
def __len__(self):
return len(self.datalist)
def __getitem__(self,idx):
audio_file_path=os.path.join(self.audio_path,self.datalist[idx])
label_file_path=os.path.join(self.label_path,self.datalist[idx][:-4]+'.json')
with open(label_file_path,'r') as f:
content=json.loads(f.read())
f.close()
label=content['cough_detected']
waveform,sample_rate=ta.load(audio_file_path) #(num_channels,samples) -> (1,samples) makes the waveform mono
waveform=waveform.to(self.device)
waveform=self._resample(waveform,sample_rate)
waveform=self._mix_down(waveform)
waveform=self._cut(waveform)
waveform=self._right_pad(waveform)
waveform=self.transformation(waveform)
return waveform,float(label)
def _resample(self,waveform,sample_rate):
# used to handle sample rate
resampler=ta.transforms.Resample(sample_rate,self.target_sample_rate)
return resampler(waveform)
def _mix_down(self,waveform):
# used to handle channels
waveform=pt.mean(waveform,dim=0,keepdim=True)
return waveform
def _cut(self,waveform):
# cuts the waveform if it has more than certain samples
if waveform.shape[1]>self.num_samples:
waveform=waveform[:,:self.num_samples]
return waveform
def _right_pad(self,waveform):
# pads the waveform if it has less than certain samples
signal_length=waveform.shape[1]
if signal_length<self.num_samples:
num_padding=self.num_samples-signal_length
last_dim_padding=(0,num_padding) # first arg for left second for right padding. Make a list of tuples for multi dim
waveform=pt.nn.functional.pad(waveform,last_dim_padding)
return waveform
melspectogram=ta.transforms.MelSpectrogram(sample_rate=SAMPLE_RATE,n_fft=1024,hop_length=512,n_mels=64)
class CNNNetwork(nn.Module):
def __init__(self):
super().__init__()
self.conv1=nn.Sequential(
nn.Conv2d(in_channels=1,out_channels=16,kernel_size=3,stride=1,padding=2),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2)
)
self.conv2=nn.Sequential(
nn.Conv2d(in_channels=16,out_channels=32,kernel_size=3,stride=1,padding=2),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2)
)
self.conv3=nn.Sequential(
nn.Conv2d(in_channels=32,out_channels=64,kernel_size=3,stride=1,padding=2),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2)
)
self.conv4=nn.Sequential(
nn.Conv2d(in_channels=64,out_channels=128,kernel_size=3,stride=1,padding=2),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2)
)
self.flatten=nn.Flatten()
self.linear1=nn.Linear(in_features=128*5*4,out_features=128)
self.linear2=nn.Linear(in_features=128,out_features=1)
self.output=nn.Sigmoid()
def forward(self,input_data):
x=self.conv1(input_data)
x=self.conv2(x)
x=self.conv3(x)
x=self.conv4(x)
x=self.flatten(x)
x=self.linear1(x)
logits=self.linear2(x)
output=self.output(logits)
return output
model=CNNNetwork().cuda()
summary(model,(1,64,44))
waveform,label=coughvid_dataset[0]
def predict(model,inputs,labels):
model.eval()
inputs=pt.unsqueeze(inputs,0)
with pt.no_grad():
predictions=model(inputs)
return predictions,labels
prediction,label=predict(model,waveform,label)
print(prediction,label)
audio_path='Path Where .wav files are stored'
label_path='Path Where json files are stored'
SAMPLE_RATE=22050
NUM_SAMPLES=22050
BATCH_SIZE=128
EPOCHS=1
melspectogram=ta.transforms.MelSpectrogram(sample_rate=SAMPLE_RATE,n_fft=1024,hop_length=512,n_mels=64)
coughvid_dataset=CoughVidDataset(audio_path,label_path,melspectogram,SAMPLE_RATE,NUM_SAMPLES,device)
train_dataloader=DataLoader(coughvid_dataset,batch_size=BATCH_SIZE,shuffle=True)
loss_fn=pt.nn.MSELoss()
optimizer=pt.optim.SGD(model.parameters(),lr=0.1,momentum=0.9)
train(model,train_dataloader,loss_fn,optimizer,device,EPOCHS)
def train_single_epoch(model,dataloader,loss_fn,optimizer,device):
for waveform,label in tqdm.tqdm(dataloader):
waveform=waveform.to(device)
# label=pt.from_numpy(numpy.array(label))
label=label.to(device)
# calculate loss and preds
logits=model(waveform)
loss=loss_fn(logits.float(),label.float().view(-1,1))
# backpropogate the loss and update the gradients
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f"loss:{loss.item()}")
def train(model,dataloader,loss_fn,optimizer,device,epochs):
for i in tqdm.tqdm(range(epochs)):
print(f"epoch:{i+1}")
train_single_epoch(model,dataloader,loss_fn,optimizer,device)
print('-------------------------------------------')
print('Finished Training')
path='Path Where .wav files are stored'
name_set=set()
for file in os.listdir(path):
if file.endswith('wav'):
name_set.add(file)
print(len(name_set))
t=os.path.join(path,list(name_set)[0])
label_path='Path where the json files are'
fname=t[8:-4]
l=os.path.join(label_path,fname+'.json')
print(fname)
with open(l,'r') as f:
content=json.loads(f.read())
print(content)
signal,sr=ta.load(t)
path='PathToFile'
for file in os.listdir(path):
if file.endswith('webm'):
subprocess.run(['ffmpeg','-i',os.path.join(path,file),'test_df/'+file[:-5]+'.wav'])
Ok so lets get started. As you can see in the code above the init, len, and getitem method are self explanatory (we are using the index to get the path of the audio file and the label). If you want to learn more about them check out the pytorch documentation. PyTorch documentation - PyTorch 1.9.0 documentation Stable: These features will be maintained long-term and there should generally be no major performance limitations or…pytorch.org
In the getitem method we are basically doing some transformations on the waveform to make it suitable for our model. The most important one of this is the Melspectrogram transformation from torch audio. This basically converts the waveform from the Hz scale to the Mel scale. The Mel Scale is constructed such that sounds of equal distance from each other on the Mel Scale, also “sound” to humans as they are equal in distance from one another. It aims to mimic the non-linear human perception of sound. For better understanding take a look at the code.
import torch as pt
from torch import nn
import torchaudio as ta
from torchsummary import summary
from torch.utils.data import Dataset,DataLoader
import numpy as numpy
import os
import subprocess
import tqdm as tqdm
import json
if pt.cuda.is_available():
device='cuda'
else:
device='cpu'
class CoughVidDataset(Dataset):
def __init__(self,audio_path,label_path,transformation,target_sample_rate,num_samples,device):
name_set=set()
for file in os.listdir(audio_path):
if file.endswith('wav'):
name_set.add(file)
name_set=list(name_set)
self.datalist=name_set
self.audio_path=audio_path
self.label_path=label_path
self.device=device
self.transformation=transformation.to(device)
self.target_sample_rate=target_sample_rate
self.num_samples=num_samples
def __len__(self):
return len(self.datalist)
def __getitem__(self,idx):
audio_file_path=os.path.join(self.audio_path,self.datalist[idx])
label_file_path=os.path.join(self.label_path,self.datalist[idx][:-4]+'.json')
with open(label_file_path,'r') as f:
content=json.loads(f.read())
f.close()
label=content['cough_detected']
waveform,sample_rate=ta.load(audio_file_path) #(num_channels,samples) -> (1,samples) makes the waveform mono
waveform=waveform.to(self.device)
waveform=self._resample(waveform,sample_rate)
waveform=self._mix_down(waveform)
waveform=self._cut(waveform)
waveform=self._right_pad(waveform)
waveform=self.transformation(waveform)
return waveform,float(label)
def _resample(self,waveform,sample_rate):
# used to handle sample rate
resampler=ta.transforms.Resample(sample_rate,self.target_sample_rate)
return resampler(waveform)
def _mix_down(self,waveform):
# used to handle channels
waveform=pt.mean(waveform,dim=0,keepdim=True)
return waveform
def _cut(self,waveform):
# cuts the waveform if it has more than certain samples
if waveform.shape[1]>self.num_samples:
waveform=waveform[:,:self.num_samples]
return waveform
def _right_pad(self,waveform):
# pads the waveform if it has less than certain samples
signal_length=waveform.shape[1]
if signal_length<self.num_samples:
num_padding=self.num_samples-signal_length
last_dim_padding=(0,num_padding) # first arg for left second for right padding. Make a list of tuples for multi dim
waveform=pt.nn.functional.pad(waveform,last_dim_padding)
return waveform
melspectogram=ta.transforms.MelSpectrogram(sample_rate=SAMPLE_RATE,n_fft=1024,hop_length=512,n_mels=64)
class CNNNetwork(nn.Module):
def __init__(self):
super().__init__()
self.conv1=nn.Sequential(
nn.Conv2d(in_channels=1,out_channels=16,kernel_size=3,stride=1,padding=2),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2)
)
self.conv2=nn.Sequential(
nn.Conv2d(in_channels=16,out_channels=32,kernel_size=3,stride=1,padding=2),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2)
)
self.conv3=nn.Sequential(
nn.Conv2d(in_channels=32,out_channels=64,kernel_size=3,stride=1,padding=2),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2)
)
self.conv4=nn.Sequential(
nn.Conv2d(in_channels=64,out_channels=128,kernel_size=3,stride=1,padding=2),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2)
)
self.flatten=nn.Flatten()
self.linear1=nn.Linear(in_features=128*5*4,out_features=128)
self.linear2=nn.Linear(in_features=128,out_features=1)
self.output=nn.Sigmoid()
def forward(self,input_data):
x=self.conv1(input_data)
x=self.conv2(x)
x=self.conv3(x)
x=self.conv4(x)
x=self.flatten(x)
x=self.linear1(x)
logits=self.linear2(x)
output=self.output(logits)
return output
model=CNNNetwork().cuda()
summary(model,(1,64,44))
waveform,label=coughvid_dataset[0]
def predict(model,inputs,labels):
model.eval()
inputs=pt.unsqueeze(inputs,0)
with pt.no_grad():
predictions=model(inputs)
return predictions,labels
prediction,label=predict(model,waveform,label)
print(prediction,label)
audio_path='Path Where .wav files are stored'
label_path='Path Where json files are stored'
SAMPLE_RATE=22050
NUM_SAMPLES=22050
BATCH_SIZE=128
EPOCHS=1
melspectogram=ta.transforms.MelSpectrogram(sample_rate=SAMPLE_RATE,n_fft=1024,hop_length=512,n_mels=64)
coughvid_dataset=CoughVidDataset(audio_path,label_path,melspectogram,SAMPLE_RATE,NUM_SAMPLES,device)
train_dataloader=DataLoader(coughvid_dataset,batch_size=BATCH_SIZE,shuffle=True)
loss_fn=pt.nn.MSELoss()
optimizer=pt.optim.SGD(model.parameters(),lr=0.1,momentum=0.9)
train(model,train_dataloader,loss_fn,optimizer,device,EPOCHS)
def train_single_epoch(model,dataloader,loss_fn,optimizer,device):
for waveform,label in tqdm.tqdm(dataloader):
waveform=waveform.to(device)
# label=pt.from_numpy(numpy.array(label))
label=label.to(device)
# calculate loss and preds
logits=model(waveform)
loss=loss_fn(logits.float(),label.float().view(-1,1))
# backpropogate the loss and update the gradients
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f"loss:{loss.item()}")
def train(model,dataloader,loss_fn,optimizer,device,epochs):
for i in tqdm.tqdm(range(epochs)):
print(f"epoch:{i+1}")
train_single_epoch(model,dataloader,loss_fn,optimizer,device)
print('-------------------------------------------')
print('Finished Training')
path='Path Where .wav files are stored'
name_set=set()
for file in os.listdir(path):
if file.endswith('wav'):
name_set.add(file)
print(len(name_set))
t=os.path.join(path,list(name_set)[0])
label_path='Path where the json files are'
fname=t[8:-4]
l=os.path.join(label_path,fname+'.json')
print(fname)
with open(l,'r') as f:
content=json.loads(f.read())
print(content)
signal,sr=ta.load(t)
path='PathToFile'
for file in os.listdir(path):
if file.endswith('webm'):
subprocess.run(['ffmpeg','-i',os.path.join(path,file),'test_df/'+file[:-5]+'.wav'])
Here the sample rate is the desired sample rate we want, n_fft (non-uniform fast fourier transform) or in the context of the code the length of the n_fft of a short segment. The hop_length is the gap between the start of one segment and the subsequent segment, this is done so that the segments don’t overlap each other completely. It is also is directly responsible for our input shape. The n_mels parameter is basically the number of Mel banks or filters in the spectrogram. Basically the amount of partitions the Hz scale has been divided into.
One way to interpret the relation between the above parameters is that frame/bit rate (of the sample) = sample_rate/hop_length. (You will notice this below when I discuss the shape of our layers).
I know this can be a little convoluted so take a look at this wonderful blog explaining the Melspectrogram in detail. Getting to Know the Mel Spectrogram Read this short post if you want to be like Neo and know all about the Mel Spectrogram!towardsdatascience.com
Also check out this stack overflow article about the code. Trying to understand shape of spectrograms and n_mels I am going through these two librosa docs: melspectrogram and stft. I am working on datasets of audio of variable…stackoverflow.com
But before we apply the transformation to our waveform lets make sure that all of our data has the same sample rate, number of channels, and duration. For this I have created a bunch of private methods. I will go over them in detail below.
_resample: This method resamples our audio signal so that it has the same sample rate as a desired target value. This is because the sample rate will directly affect the bounds of our Hz scale and in turn our Mel scale.
_mix_down: This method will make sure our audio signal has only one channel (will turn it into a “mono” signal). It does so by aggregating all the channels into one.
_cut: This method cuts the duration of the audio signal if it is greater than a certain length i.e. if it has more than a certain length of samples.
_right_pad: This method is the opposite of the _cut method i.e. it right pads the audio signal if it has less than the desired number of samples.
After applying all of these pre processing steps we finally transform our audio signal into a Melspectrogram and return it along with our labels.
3. ML Modelling
Phew 😅 the last section was a bit overwhelming so lets get into some model building. For this I am not going to go into some complex model architecture since the goal of this blog is to just cover the basics. So for this task we will be using a simple CNN model. I know you are wondering how can a CNN model that is used mainly for computer vision be used for an audio task, aren’t audio and video different?
Yes they are. But our audio signal/waveform after preprocessing can be interpreted as a 2d image (frequency X time). Surprisingly CNN’s are efficacious when it comes to audio data. For better understanding read this blog, the model I will show you is also heavily inspired from here. Audio Classification Using CNN — Coding Example CNN is best suited for images. Leveraging its power to classify spoken digit sounds with 97% accuracy.medium.com
import torch as pt
from torch import nn
import torchaudio as ta
from torchsummary import summary
from torch.utils.data import Dataset,DataLoader
import numpy as numpy
import os
import subprocess
import tqdm as tqdm
import json
if pt.cuda.is_available():
device='cuda'
else:
device='cpu'
class CoughVidDataset(Dataset):
def __init__(self,audio_path,label_path,transformation,target_sample_rate,num_samples,device):
name_set=set()
for file in os.listdir(audio_path):
if file.endswith('wav'):
name_set.add(file)
name_set=list(name_set)
self.datalist=name_set
self.audio_path=audio_path
self.label_path=label_path
self.device=device
self.transformation=transformation.to(device)
self.target_sample_rate=target_sample_rate
self.num_samples=num_samples
def __len__(self):
return len(self.datalist)
def __getitem__(self,idx):
audio_file_path=os.path.join(self.audio_path,self.datalist[idx])
label_file_path=os.path.join(self.label_path,self.datalist[idx][:-4]+'.json')
with open(label_file_path,'r') as f:
content=json.loads(f.read())
f.close()
label=content['cough_detected']
waveform,sample_rate=ta.load(audio_file_path) #(num_channels,samples) -> (1,samples) makes the waveform mono
waveform=waveform.to(self.device)
waveform=self._resample(waveform,sample_rate)
waveform=self._mix_down(waveform)
waveform=self._cut(waveform)
waveform=self._right_pad(waveform)
waveform=self.transformation(waveform)
return waveform,float(label)
def _resample(self,waveform,sample_rate):
# used to handle sample rate
resampler=ta.transforms.Resample(sample_rate,self.target_sample_rate)
return resampler(waveform)
def _mix_down(self,waveform):
# used to handle channels
waveform=pt.mean(waveform,dim=0,keepdim=True)
return waveform
def _cut(self,waveform):
# cuts the waveform if it has more than certain samples
if waveform.shape[1]>self.num_samples:
waveform=waveform[:,:self.num_samples]
return waveform
def _right_pad(self,waveform):
# pads the waveform if it has less than certain samples
signal_length=waveform.shape[1]
if signal_length<self.num_samples:
num_padding=self.num_samples-signal_length
last_dim_padding=(0,num_padding) # first arg for left second for right padding. Make a list of tuples for multi dim
waveform=pt.nn.functional.pad(waveform,last_dim_padding)
return waveform
melspectogram=ta.transforms.MelSpectrogram(sample_rate=SAMPLE_RATE,n_fft=1024,hop_length=512,n_mels=64)
class CNNNetwork(nn.Module):
def __init__(self):
super().__init__()
self.conv1=nn.Sequential(
nn.Conv2d(in_channels=1,out_channels=16,kernel_size=3,stride=1,padding=2),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2)
)
self.conv2=nn.Sequential(
nn.Conv2d(in_channels=16,out_channels=32,kernel_size=3,stride=1,padding=2),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2)
)
self.conv3=nn.Sequential(
nn.Conv2d(in_channels=32,out_channels=64,kernel_size=3,stride=1,padding=2),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2)
)
self.conv4=nn.Sequential(
nn.Conv2d(in_channels=64,out_channels=128,kernel_size=3,stride=1,padding=2),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2)
)
self.flatten=nn.Flatten()
self.linear1=nn.Linear(in_features=128*5*4,out_features=128)
self.linear2=nn.Linear(in_features=128,out_features=1)
self.output=nn.Sigmoid()
def forward(self,input_data):
x=self.conv1(input_data)
x=self.conv2(x)
x=self.conv3(x)
x=self.conv4(x)
x=self.flatten(x)
x=self.linear1(x)
logits=self.linear2(x)
output=self.output(logits)
return output
model=CNNNetwork().cuda()
summary(model,(1,64,44))
waveform,label=coughvid_dataset[0]
def predict(model,inputs,labels):
model.eval()
inputs=pt.unsqueeze(inputs,0)
with pt.no_grad():
predictions=model(inputs)
return predictions,labels
prediction,label=predict(model,waveform,label)
print(prediction,label)
audio_path='Path Where .wav files are stored'
label_path='Path Where json files are stored'
SAMPLE_RATE=22050
NUM_SAMPLES=22050
BATCH_SIZE=128
EPOCHS=1
melspectogram=ta.transforms.MelSpectrogram(sample_rate=SAMPLE_RATE,n_fft=1024,hop_length=512,n_mels=64)
coughvid_dataset=CoughVidDataset(audio_path,label_path,melspectogram,SAMPLE_RATE,NUM_SAMPLES,device)
train_dataloader=DataLoader(coughvid_dataset,batch_size=BATCH_SIZE,shuffle=True)
loss_fn=pt.nn.MSELoss()
optimizer=pt.optim.SGD(model.parameters(),lr=0.1,momentum=0.9)
train(model,train_dataloader,loss_fn,optimizer,device,EPOCHS)
def train_single_epoch(model,dataloader,loss_fn,optimizer,device):
for waveform,label in tqdm.tqdm(dataloader):
waveform=waveform.to(device)
# label=pt.from_numpy(numpy.array(label))
label=label.to(device)
# calculate loss and preds
logits=model(waveform)
loss=loss_fn(logits.float(),label.float().view(-1,1))
# backpropogate the loss and update the gradients
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f"loss:{loss.item()}")
def train(model,dataloader,loss_fn,optimizer,device,epochs):
for i in tqdm.tqdm(range(epochs)):
print(f"epoch:{i+1}")
train_single_epoch(model,dataloader,loss_fn,optimizer,device)
print('-------------------------------------------')
print('Finished Training')
path='Path Where .wav files are stored'
name_set=set()
for file in os.listdir(path):
if file.endswith('wav'):
name_set.add(file)
print(len(name_set))
t=os.path.join(path,list(name_set)[0])
label_path='Path where the json files are'
fname=t[8:-4]
l=os.path.join(label_path,fname+'.json')
print(fname)
with open(l,'r') as f:
content=json.loads(f.read())
print(content)
signal,sr=ta.load(t)
path='PathToFile'
for file in os.listdir(path):
if file.endswith('webm'):
subprocess.run(['ffmpeg','-i',os.path.join(path,file),'test_df/'+file[:-5]+'.wav'])
The above is the code for our model. It has 4 convolution blocks each consisting of a Conv2d layer with a relu activation function followed by a max pooling layer to reduce the image (spectrogram) size by 2. The convolution blocks are followed by a simple flatten layer, a couple of linear/Dense layers and finally the output layer which in our case is the sigmoid layer since our outputs are bounded between 0 and 1. In case this was a classification task you would’ve just replaced the sigmoid layer with a softmax or log softmax layer.
That’s it our model is done. This is a pretty standard architecture and there are many more NN architectures that will give you a better result than this. Just recently I came across another architecture which fed the Convolution block outputs to a GRU and also incorporated residual learning fundamentals. If you are interested in improving your accuracy give this model a try.
Now I have also used torch summary (a very useful package to generate your model summaries) to generate our model summary.
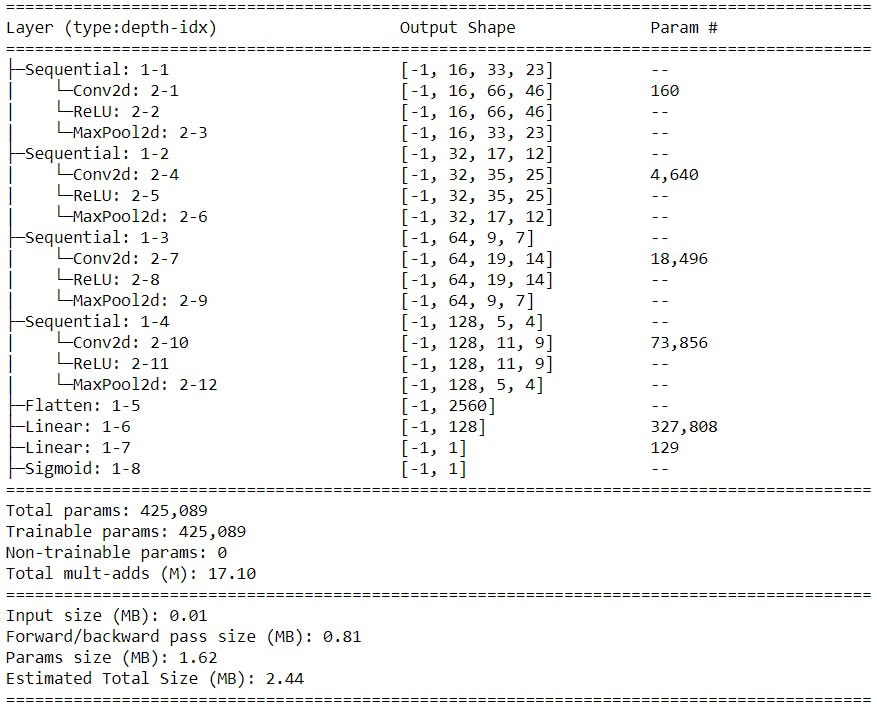 Model summary with layer dimensions
Model summary with layer dimensions
As you can see beside the conv2d 2–1 layer our input shape is (-1,16,66,46). 16 is the number of filters, after subtracting 2 which is the padding we get (64,44) which is nothing but (n_mels, sample_rate/hop_length) like discussed above.
4. Training and Prediction
Moving on to the final section, lets just define some basic training utility functions that will make our lives easier, since pytorch doesn’t have a built in fit method like tensorflow. You colud also use pytorch-lightning for this. PyTorch Lightning import torchfrom torch import nnfrom torch.nn import functional as Ffrom torch.utils.data import DataLoaderfrom…pytorchlightning.ai
import torch as pt
from torch import nn
import torchaudio as ta
from torchsummary import summary
from torch.utils.data import Dataset,DataLoader
import numpy as numpy
import os
import subprocess
import tqdm as tqdm
import json
if pt.cuda.is_available():
device='cuda'
else:
device='cpu'
class CoughVidDataset(Dataset):
def __init__(self,audio_path,label_path,transformation,target_sample_rate,num_samples,device):
name_set=set()
for file in os.listdir(audio_path):
if file.endswith('wav'):
name_set.add(file)
name_set=list(name_set)
self.datalist=name_set
self.audio_path=audio_path
self.label_path=label_path
self.device=device
self.transformation=transformation.to(device)
self.target_sample_rate=target_sample_rate
self.num_samples=num_samples
def __len__(self):
return len(self.datalist)
def __getitem__(self,idx):
audio_file_path=os.path.join(self.audio_path,self.datalist[idx])
label_file_path=os.path.join(self.label_path,self.datalist[idx][:-4]+'.json')
with open(label_file_path,'r') as f:
content=json.loads(f.read())
f.close()
label=content['cough_detected']
waveform,sample_rate=ta.load(audio_file_path) #(num_channels,samples) -> (1,samples) makes the waveform mono
waveform=waveform.to(self.device)
waveform=self._resample(waveform,sample_rate)
waveform=self._mix_down(waveform)
waveform=self._cut(waveform)
waveform=self._right_pad(waveform)
waveform=self.transformation(waveform)
return waveform,float(label)
def _resample(self,waveform,sample_rate):
# used to handle sample rate
resampler=ta.transforms.Resample(sample_rate,self.target_sample_rate)
return resampler(waveform)
def _mix_down(self,waveform):
# used to handle channels
waveform=pt.mean(waveform,dim=0,keepdim=True)
return waveform
def _cut(self,waveform):
# cuts the waveform if it has more than certain samples
if waveform.shape[1]>self.num_samples:
waveform=waveform[:,:self.num_samples]
return waveform
def _right_pad(self,waveform):
# pads the waveform if it has less than certain samples
signal_length=waveform.shape[1]
if signal_length<self.num_samples:
num_padding=self.num_samples-signal_length
last_dim_padding=(0,num_padding) # first arg for left second for right padding. Make a list of tuples for multi dim
waveform=pt.nn.functional.pad(waveform,last_dim_padding)
return waveform
melspectogram=ta.transforms.MelSpectrogram(sample_rate=SAMPLE_RATE,n_fft=1024,hop_length=512,n_mels=64)
class CNNNetwork(nn.Module):
def __init__(self):
super().__init__()
self.conv1=nn.Sequential(
nn.Conv2d(in_channels=1,out_channels=16,kernel_size=3,stride=1,padding=2),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2)
)
self.conv2=nn.Sequential(
nn.Conv2d(in_channels=16,out_channels=32,kernel_size=3,stride=1,padding=2),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2)
)
self.conv3=nn.Sequential(
nn.Conv2d(in_channels=32,out_channels=64,kernel_size=3,stride=1,padding=2),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2)
)
self.conv4=nn.Sequential(
nn.Conv2d(in_channels=64,out_channels=128,kernel_size=3,stride=1,padding=2),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2)
)
self.flatten=nn.Flatten()
self.linear1=nn.Linear(in_features=128*5*4,out_features=128)
self.linear2=nn.Linear(in_features=128,out_features=1)
self.output=nn.Sigmoid()
def forward(self,input_data):
x=self.conv1(input_data)
x=self.conv2(x)
x=self.conv3(x)
x=self.conv4(x)
x=self.flatten(x)
x=self.linear1(x)
logits=self.linear2(x)
output=self.output(logits)
return output
model=CNNNetwork().cuda()
summary(model,(1,64,44))
waveform,label=coughvid_dataset[0]
def predict(model,inputs,labels):
model.eval()
inputs=pt.unsqueeze(inputs,0)
with pt.no_grad():
predictions=model(inputs)
return predictions,labels
prediction,label=predict(model,waveform,label)
print(prediction,label)
audio_path='Path Where .wav files are stored'
label_path='Path Where json files are stored'
SAMPLE_RATE=22050
NUM_SAMPLES=22050
BATCH_SIZE=128
EPOCHS=1
melspectogram=ta.transforms.MelSpectrogram(sample_rate=SAMPLE_RATE,n_fft=1024,hop_length=512,n_mels=64)
coughvid_dataset=CoughVidDataset(audio_path,label_path,melspectogram,SAMPLE_RATE,NUM_SAMPLES,device)
train_dataloader=DataLoader(coughvid_dataset,batch_size=BATCH_SIZE,shuffle=True)
loss_fn=pt.nn.MSELoss()
optimizer=pt.optim.SGD(model.parameters(),lr=0.1,momentum=0.9)
train(model,train_dataloader,loss_fn,optimizer,device,EPOCHS)
def train_single_epoch(model,dataloader,loss_fn,optimizer,device):
for waveform,label in tqdm.tqdm(dataloader):
waveform=waveform.to(device)
# label=pt.from_numpy(numpy.array(label))
label=label.to(device)
# calculate loss and preds
logits=model(waveform)
loss=loss_fn(logits.float(),label.float().view(-1,1))
# backpropogate the loss and update the gradients
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f"loss:{loss.item()}")
def train(model,dataloader,loss_fn,optimizer,device,epochs):
for i in tqdm.tqdm(range(epochs)):
print(f"epoch:{i+1}")
train_single_epoch(model,dataloader,loss_fn,optimizer,device)
print('-------------------------------------------')
print('Finished Training')
path='Path Where .wav files are stored'
name_set=set()
for file in os.listdir(path):
if file.endswith('wav'):
name_set.add(file)
print(len(name_set))
t=os.path.join(path,list(name_set)[0])
label_path='Path where the json files are'
fname=t[8:-4]
l=os.path.join(label_path,fname+'.json')
print(fname)
with open(l,'r') as f:
content=json.loads(f.read())
print(content)
signal,sr=ta.load(t)
path='PathToFile'
for file in os.listdir(path):
if file.endswith('webm'):
subprocess.run(['ffmpeg','-i',os.path.join(path,file),'test_df/'+file[:-5]+'.wav'])
Here the train function just trains the model using the train_single_epoch function. The values and constants and other training code is below. Nothing more to explain in this part, if you have any difficulties check out the pytorch docs.
import torch as pt
from torch import nn
import torchaudio as ta
from torchsummary import summary
from torch.utils.data import Dataset,DataLoader
import numpy as numpy
import os
import subprocess
import tqdm as tqdm
import json
if pt.cuda.is_available():
device='cuda'
else:
device='cpu'
class CoughVidDataset(Dataset):
def __init__(self,audio_path,label_path,transformation,target_sample_rate,num_samples,device):
name_set=set()
for file in os.listdir(audio_path):
if file.endswith('wav'):
name_set.add(file)
name_set=list(name_set)
self.datalist=name_set
self.audio_path=audio_path
self.label_path=label_path
self.device=device
self.transformation=transformation.to(device)
self.target_sample_rate=target_sample_rate
self.num_samples=num_samples
def __len__(self):
return len(self.datalist)
def __getitem__(self,idx):
audio_file_path=os.path.join(self.audio_path,self.datalist[idx])
label_file_path=os.path.join(self.label_path,self.datalist[idx][:-4]+'.json')
with open(label_file_path,'r') as f:
content=json.loads(f.read())
f.close()
label=content['cough_detected']
waveform,sample_rate=ta.load(audio_file_path) #(num_channels,samples) -> (1,samples) makes the waveform mono
waveform=waveform.to(self.device)
waveform=self._resample(waveform,sample_rate)
waveform=self._mix_down(waveform)
waveform=self._cut(waveform)
waveform=self._right_pad(waveform)
waveform=self.transformation(waveform)
return waveform,float(label)
def _resample(self,waveform,sample_rate):
# used to handle sample rate
resampler=ta.transforms.Resample(sample_rate,self.target_sample_rate)
return resampler(waveform)
def _mix_down(self,waveform):
# used to handle channels
waveform=pt.mean(waveform,dim=0,keepdim=True)
return waveform
def _cut(self,waveform):
# cuts the waveform if it has more than certain samples
if waveform.shape[1]>self.num_samples:
waveform=waveform[:,:self.num_samples]
return waveform
def _right_pad(self,waveform):
# pads the waveform if it has less than certain samples
signal_length=waveform.shape[1]
if signal_length<self.num_samples:
num_padding=self.num_samples-signal_length
last_dim_padding=(0,num_padding) # first arg for left second for right padding. Make a list of tuples for multi dim
waveform=pt.nn.functional.pad(waveform,last_dim_padding)
return waveform
melspectogram=ta.transforms.MelSpectrogram(sample_rate=SAMPLE_RATE,n_fft=1024,hop_length=512,n_mels=64)
class CNNNetwork(nn.Module):
def __init__(self):
super().__init__()
self.conv1=nn.Sequential(
nn.Conv2d(in_channels=1,out_channels=16,kernel_size=3,stride=1,padding=2),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2)
)
self.conv2=nn.Sequential(
nn.Conv2d(in_channels=16,out_channels=32,kernel_size=3,stride=1,padding=2),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2)
)
self.conv3=nn.Sequential(
nn.Conv2d(in_channels=32,out_channels=64,kernel_size=3,stride=1,padding=2),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2)
)
self.conv4=nn.Sequential(
nn.Conv2d(in_channels=64,out_channels=128,kernel_size=3,stride=1,padding=2),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2)
)
self.flatten=nn.Flatten()
self.linear1=nn.Linear(in_features=128*5*4,out_features=128)
self.linear2=nn.Linear(in_features=128,out_features=1)
self.output=nn.Sigmoid()
def forward(self,input_data):
x=self.conv1(input_data)
x=self.conv2(x)
x=self.conv3(x)
x=self.conv4(x)
x=self.flatten(x)
x=self.linear1(x)
logits=self.linear2(x)
output=self.output(logits)
return output
model=CNNNetwork().cuda()
summary(model,(1,64,44))
waveform,label=coughvid_dataset[0]
def predict(model,inputs,labels):
model.eval()
inputs=pt.unsqueeze(inputs,0)
with pt.no_grad():
predictions=model(inputs)
return predictions,labels
prediction,label=predict(model,waveform,label)
print(prediction,label)
audio_path='Path Where .wav files are stored'
label_path='Path Where json files are stored'
SAMPLE_RATE=22050
NUM_SAMPLES=22050
BATCH_SIZE=128
EPOCHS=1
melspectogram=ta.transforms.MelSpectrogram(sample_rate=SAMPLE_RATE,n_fft=1024,hop_length=512,n_mels=64)
coughvid_dataset=CoughVidDataset(audio_path,label_path,melspectogram,SAMPLE_RATE,NUM_SAMPLES,device)
train_dataloader=DataLoader(coughvid_dataset,batch_size=BATCH_SIZE,shuffle=True)
loss_fn=pt.nn.MSELoss()
optimizer=pt.optim.SGD(model.parameters(),lr=0.1,momentum=0.9)
train(model,train_dataloader,loss_fn,optimizer,device,EPOCHS)
def train_single_epoch(model,dataloader,loss_fn,optimizer,device):
for waveform,label in tqdm.tqdm(dataloader):
waveform=waveform.to(device)
# label=pt.from_numpy(numpy.array(label))
label=label.to(device)
# calculate loss and preds
logits=model(waveform)
loss=loss_fn(logits.float(),label.float().view(-1,1))
# backpropogate the loss and update the gradients
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f"loss:{loss.item()}")
def train(model,dataloader,loss_fn,optimizer,device,epochs):
for i in tqdm.tqdm(range(epochs)):
print(f"epoch:{i+1}")
train_single_epoch(model,dataloader,loss_fn,optimizer,device)
print('-------------------------------------------')
print('Finished Training')
path='Path Where .wav files are stored'
name_set=set()
for file in os.listdir(path):
if file.endswith('wav'):
name_set.add(file)
print(len(name_set))
t=os.path.join(path,list(name_set)[0])
label_path='Path where the json files are'
fname=t[8:-4]
l=os.path.join(label_path,fname+'.json')
print(fname)
with open(l,'r') as f:
content=json.loads(f.read())
print(content)
signal,sr=ta.load(t)
path='PathToFile'
for file in os.listdir(path):
if file.endswith('webm'):
subprocess.run(['ffmpeg','-i',os.path.join(path,file),'test_df/'+file[:-5]+'.wav'])
And here is the code for running the prediction functions.
import torch as pt
from torch import nn
import torchaudio as ta
from torchsummary import summary
from torch.utils.data import Dataset,DataLoader
import numpy as numpy
import os
import subprocess
import tqdm as tqdm
import json
if pt.cuda.is_available():
device='cuda'
else:
device='cpu'
class CoughVidDataset(Dataset):
def __init__(self,audio_path,label_path,transformation,target_sample_rate,num_samples,device):
name_set=set()
for file in os.listdir(audio_path):
if file.endswith('wav'):
name_set.add(file)
name_set=list(name_set)
self.datalist=name_set
self.audio_path=audio_path
self.label_path=label_path
self.device=device
self.transformation=transformation.to(device)
self.target_sample_rate=target_sample_rate
self.num_samples=num_samples
def __len__(self):
return len(self.datalist)
def __getitem__(self,idx):
audio_file_path=os.path.join(self.audio_path,self.datalist[idx])
label_file_path=os.path.join(self.label_path,self.datalist[idx][:-4]+'.json')
with open(label_file_path,'r') as f:
content=json.loads(f.read())
f.close()
label=content['cough_detected']
waveform,sample_rate=ta.load(audio_file_path) #(num_channels,samples) -> (1,samples) makes the waveform mono
waveform=waveform.to(self.device)
waveform=self._resample(waveform,sample_rate)
waveform=self._mix_down(waveform)
waveform=self._cut(waveform)
waveform=self._right_pad(waveform)
waveform=self.transformation(waveform)
return waveform,float(label)
def _resample(self,waveform,sample_rate):
# used to handle sample rate
resampler=ta.transforms.Resample(sample_rate,self.target_sample_rate)
return resampler(waveform)
def _mix_down(self,waveform):
# used to handle channels
waveform=pt.mean(waveform,dim=0,keepdim=True)
return waveform
def _cut(self,waveform):
# cuts the waveform if it has more than certain samples
if waveform.shape[1]>self.num_samples:
waveform=waveform[:,:self.num_samples]
return waveform
def _right_pad(self,waveform):
# pads the waveform if it has less than certain samples
signal_length=waveform.shape[1]
if signal_length<self.num_samples:
num_padding=self.num_samples-signal_length
last_dim_padding=(0,num_padding) # first arg for left second for right padding. Make a list of tuples for multi dim
waveform=pt.nn.functional.pad(waveform,last_dim_padding)
return waveform
melspectogram=ta.transforms.MelSpectrogram(sample_rate=SAMPLE_RATE,n_fft=1024,hop_length=512,n_mels=64)
class CNNNetwork(nn.Module):
def __init__(self):
super().__init__()
self.conv1=nn.Sequential(
nn.Conv2d(in_channels=1,out_channels=16,kernel_size=3,stride=1,padding=2),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2)
)
self.conv2=nn.Sequential(
nn.Conv2d(in_channels=16,out_channels=32,kernel_size=3,stride=1,padding=2),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2)
)
self.conv3=nn.Sequential(
nn.Conv2d(in_channels=32,out_channels=64,kernel_size=3,stride=1,padding=2),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2)
)
self.conv4=nn.Sequential(
nn.Conv2d(in_channels=64,out_channels=128,kernel_size=3,stride=1,padding=2),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2)
)
self.flatten=nn.Flatten()
self.linear1=nn.Linear(in_features=128*5*4,out_features=128)
self.linear2=nn.Linear(in_features=128,out_features=1)
self.output=nn.Sigmoid()
def forward(self,input_data):
x=self.conv1(input_data)
x=self.conv2(x)
x=self.conv3(x)
x=self.conv4(x)
x=self.flatten(x)
x=self.linear1(x)
logits=self.linear2(x)
output=self.output(logits)
return output
model=CNNNetwork().cuda()
summary(model,(1,64,44))
waveform,label=coughvid_dataset[0]
def predict(model,inputs,labels):
model.eval()
inputs=pt.unsqueeze(inputs,0)
with pt.no_grad():
predictions=model(inputs)
return predictions,labels
prediction,label=predict(model,waveform,label)
print(prediction,label)
audio_path='Path Where .wav files are stored'
label_path='Path Where json files are stored'
SAMPLE_RATE=22050
NUM_SAMPLES=22050
BATCH_SIZE=128
EPOCHS=1
melspectogram=ta.transforms.MelSpectrogram(sample_rate=SAMPLE_RATE,n_fft=1024,hop_length=512,n_mels=64)
coughvid_dataset=CoughVidDataset(audio_path,label_path,melspectogram,SAMPLE_RATE,NUM_SAMPLES,device)
train_dataloader=DataLoader(coughvid_dataset,batch_size=BATCH_SIZE,shuffle=True)
loss_fn=pt.nn.MSELoss()
optimizer=pt.optim.SGD(model.parameters(),lr=0.1,momentum=0.9)
train(model,train_dataloader,loss_fn,optimizer,device,EPOCHS)
def train_single_epoch(model,dataloader,loss_fn,optimizer,device):
for waveform,label in tqdm.tqdm(dataloader):
waveform=waveform.to(device)
# label=pt.from_numpy(numpy.array(label))
label=label.to(device)
# calculate loss and preds
logits=model(waveform)
loss=loss_fn(logits.float(),label.float().view(-1,1))
# backpropogate the loss and update the gradients
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f"loss:{loss.item()}")
def train(model,dataloader,loss_fn,optimizer,device,epochs):
for i in tqdm.tqdm(range(epochs)):
print(f"epoch:{i+1}")
train_single_epoch(model,dataloader,loss_fn,optimizer,device)
print('-------------------------------------------')
print('Finished Training')
path='Path Where .wav files are stored'
name_set=set()
for file in os.listdir(path):
if file.endswith('wav'):
name_set.add(file)
print(len(name_set))
t=os.path.join(path,list(name_set)[0])
label_path='Path where the json files are'
fname=t[8:-4]
l=os.path.join(label_path,fname+'.json')
print(fname)
with open(l,'r') as f:
content=json.loads(f.read())
print(content)
signal,sr=ta.load(t)
path='PathToFile'
for file in os.listdir(path):
if file.endswith('webm'):
subprocess.run(['ffmpeg','-i',os.path.join(path,file),'test_df/'+file[:-5]+'.wav'])
That’s it hope it was useful to you. 😃
For the code check out my github repository. GitHub - bamblebam/covid-cough-audio-analysis Contribute to bamblebam/covid-cough-audio-analysis development by creating an account on GitHub.github.com
This blog was heavily inspired from this youtube playlist so if you want some additional resources check it out.
Burhanuddin Rangwala the author of this blog is an aspiring Data Scientist and Machine Learning Engineer who also works as a freelance web developer and writer. Hit him up at linkedIn for any work or freelance opportunities. Burhanuddin Rangwala - University Leader - Community Classroom | LinkedIn View Burhanuddin Rangwala's profile on LinkedIn, the world's largest professional community. Burhanuddin has 7 jobs…linkedin.com